Enhancing OpenRCT2 performance: a journey with Cody and SIMD
SIMD, Single Instruction Multiple Data, is a way of speeding up computationally intensive tasks by applying the same operation to multiple data items in one go. For this to be applicable, some requirements need to be met, such as data layout or access patterns.
In OpenRCT2 (free and open source remake of RollerCoaster Tycoon 2) we care a lot about performance and there’s long been a piece of code I suspected could be improved by applying the SIMD approach. I’ve been putting it off due to having to write a lot of code that probably wouldn’t make it to the repository, but I found Cody doesn’t complain about any of that and it dutifully came to help.
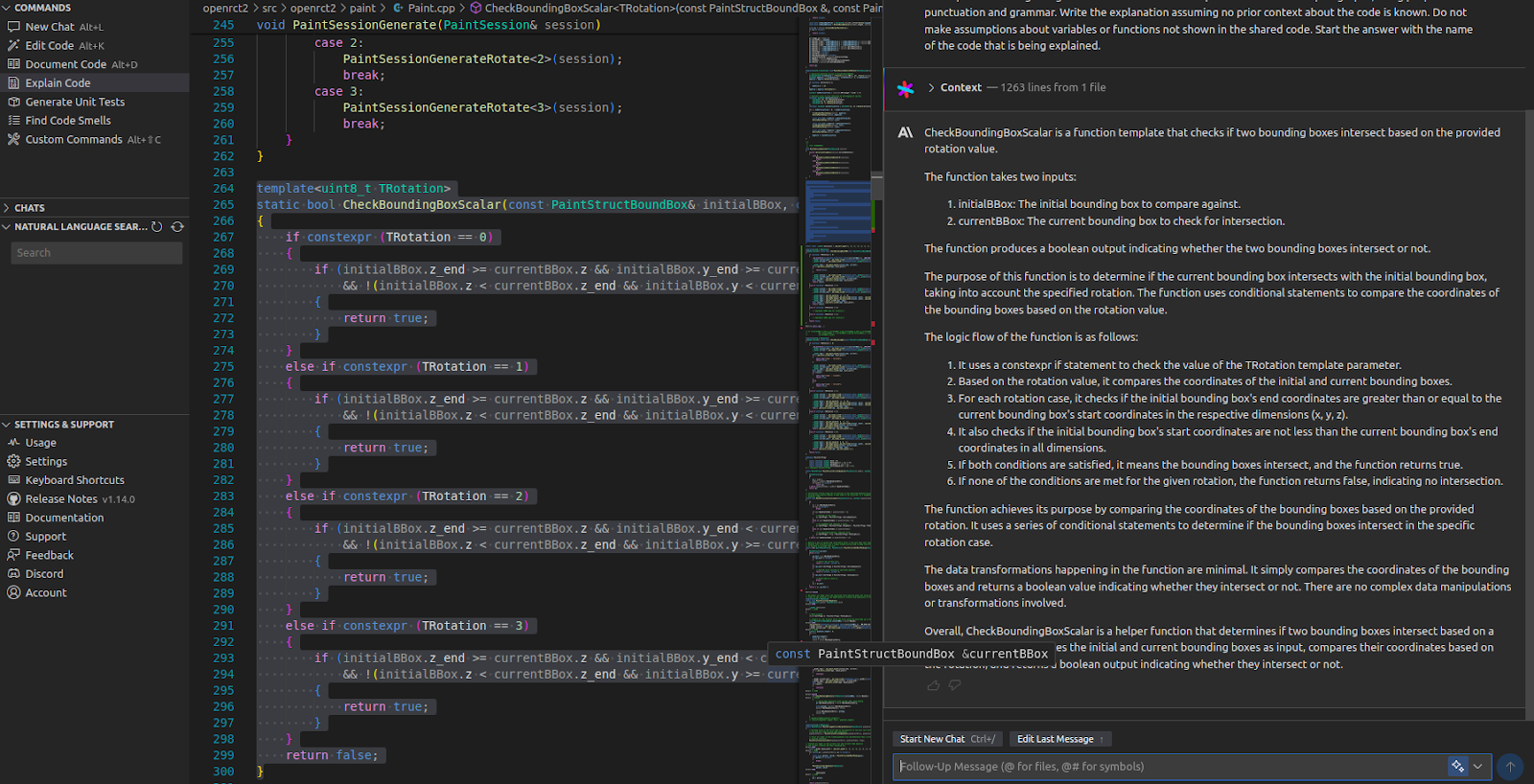
The code in question is used for arranging paint order and implements checking of bounding box intersections. With a single click of Explain Code, Cody explains in detail the responsibilities of this function:
Before we start changing anything, let's generate some tests. With the function still highlighted, that's just one more click on Generate Unit Tests.
Cody explained it didn’t know what testing framework I used and assumed (correctly, as many C++ projects do) that I use GoogleTest. It then proceeded to generate test cases for all available scenarios. After a minor cleanup from the comments left in the code, I had my tests ready. The template was correctly recognized and had tests generated. The inclusion of a .cpp file instead of .h surprised me, but it was the correct approach for testing a static function without having to remove the modifier.
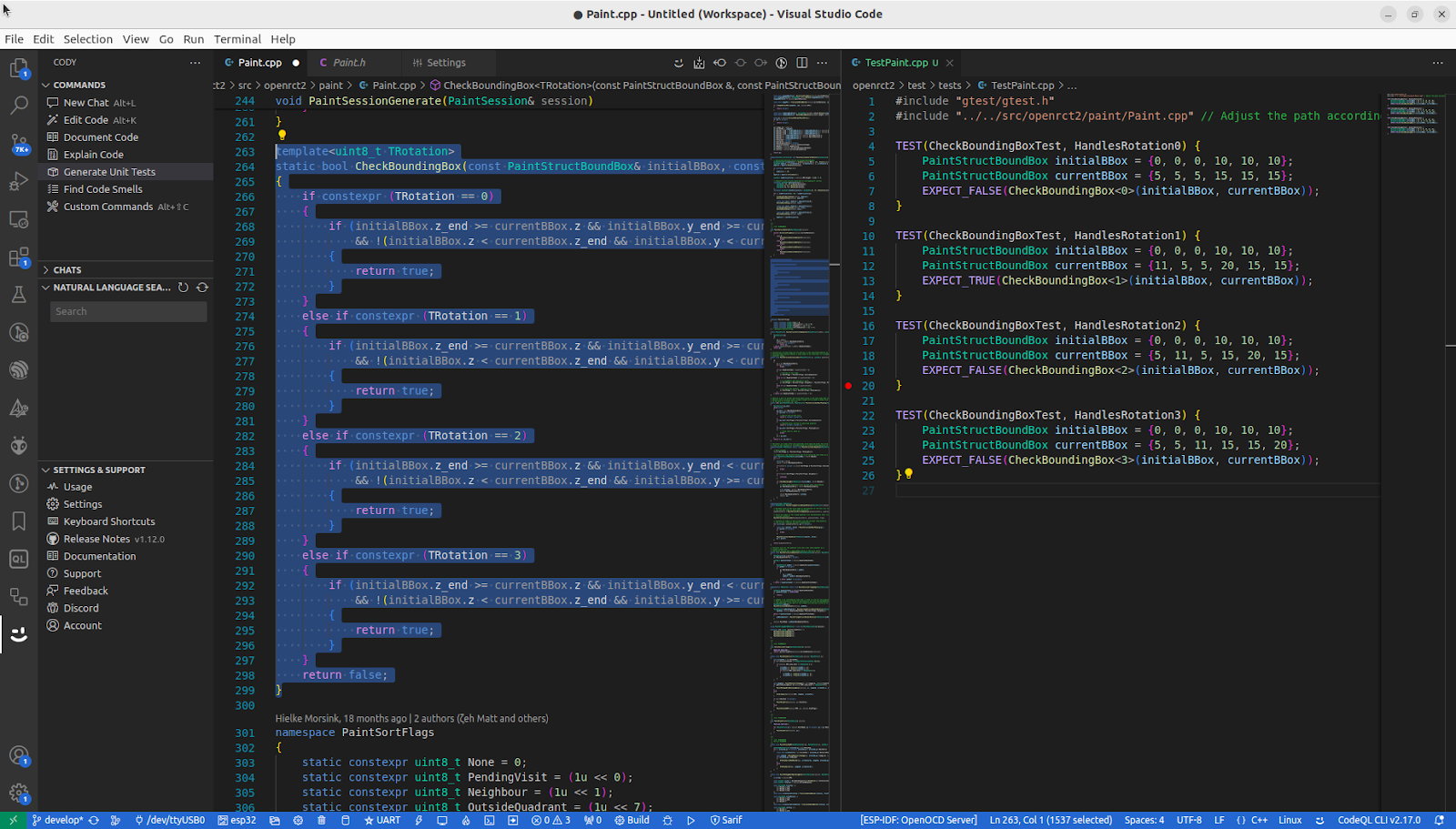
Helpful instructions on how to set up the tests with my project are easily provided
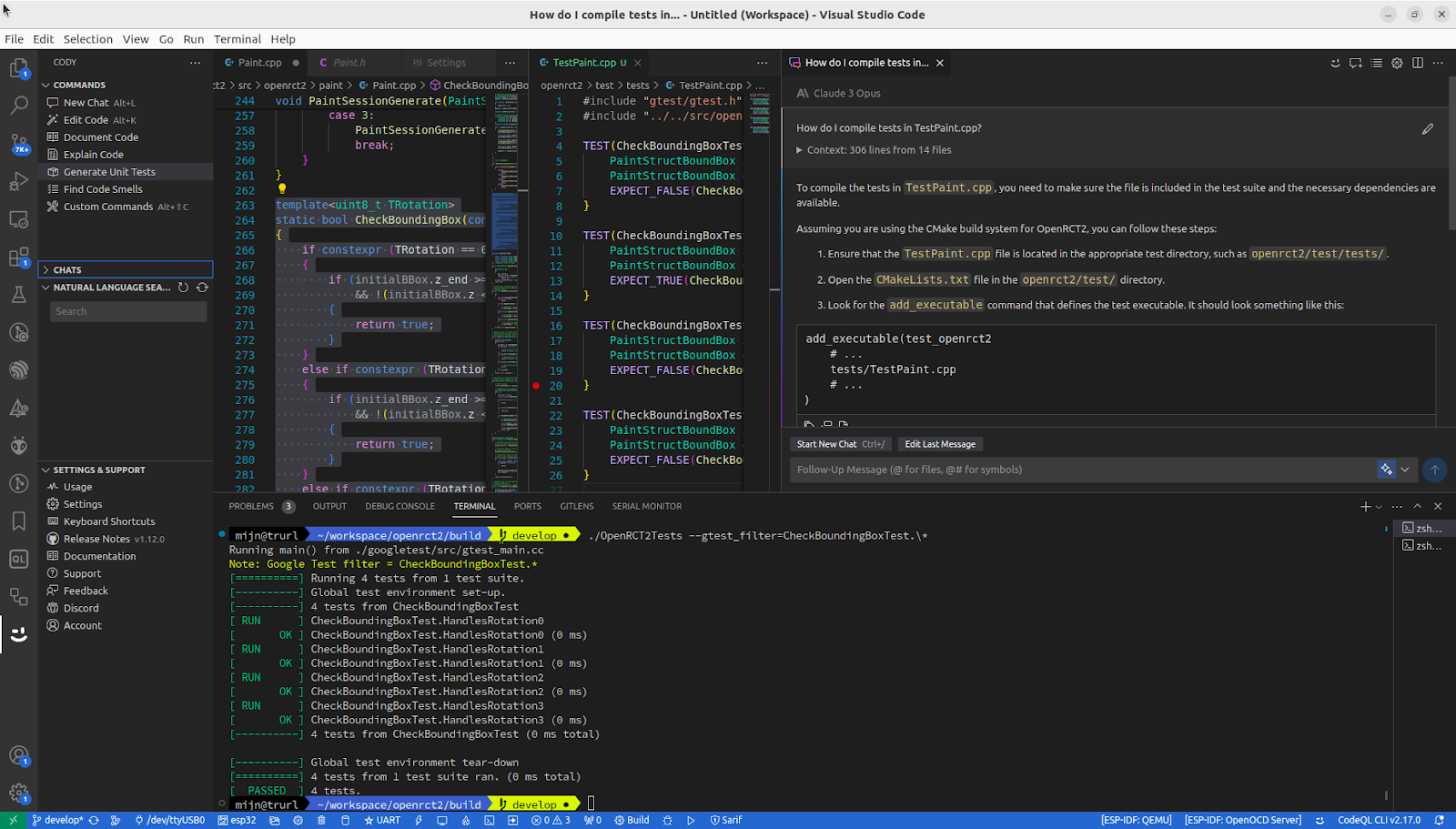
The first rule of performance tuning is you need to have data to verify your assumptions and measure any gains or losses. Using the prompt Please write Google Benchmark for highlighted code opened a new file filled with a simple benchmark I could use as a starting point.
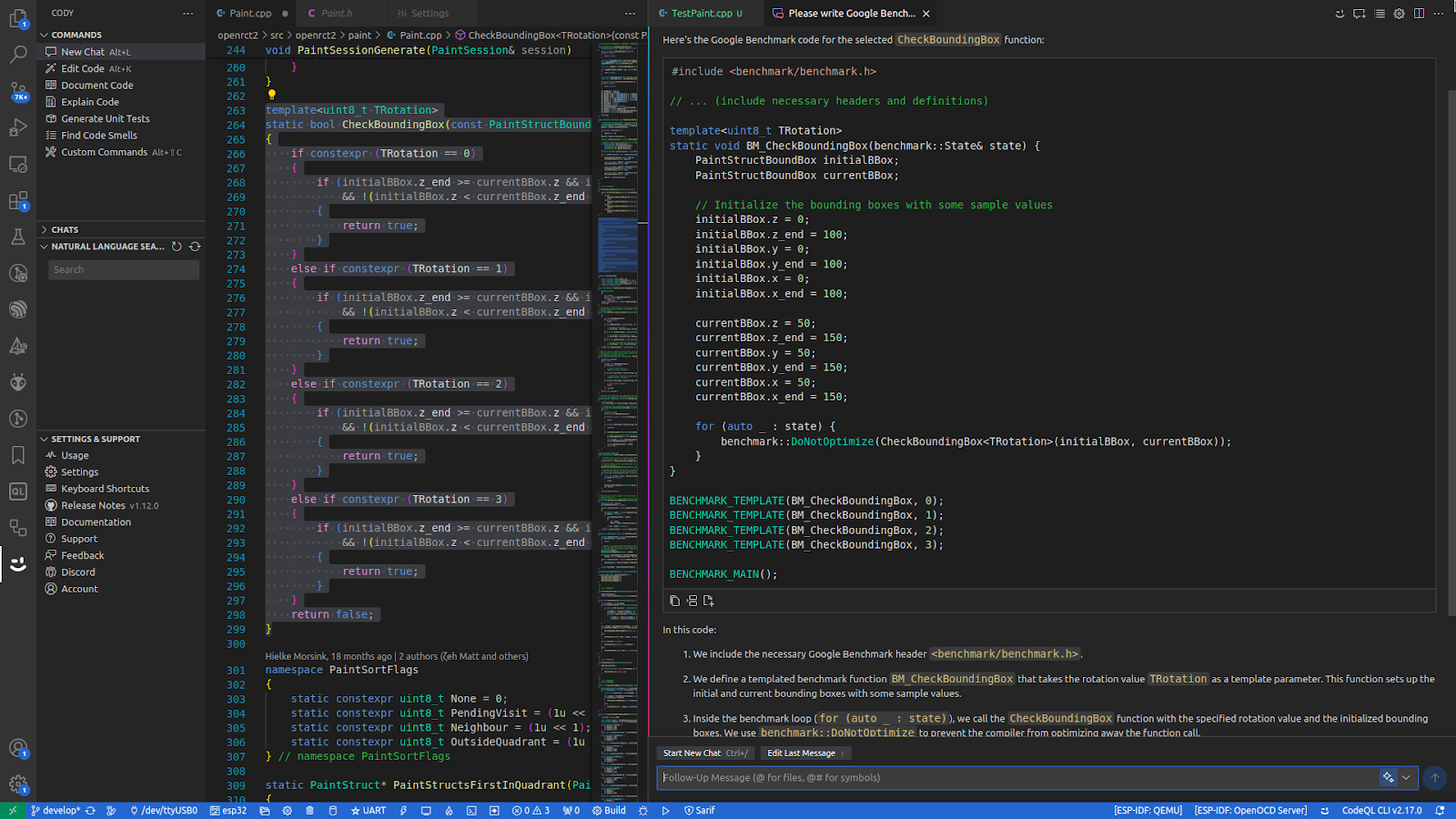
With all the tests and benchmarks at the ready, let’s actually apply some SIMD. Rewrite selected function with x86 SIMD intrinsics implemented what I long had in mind.
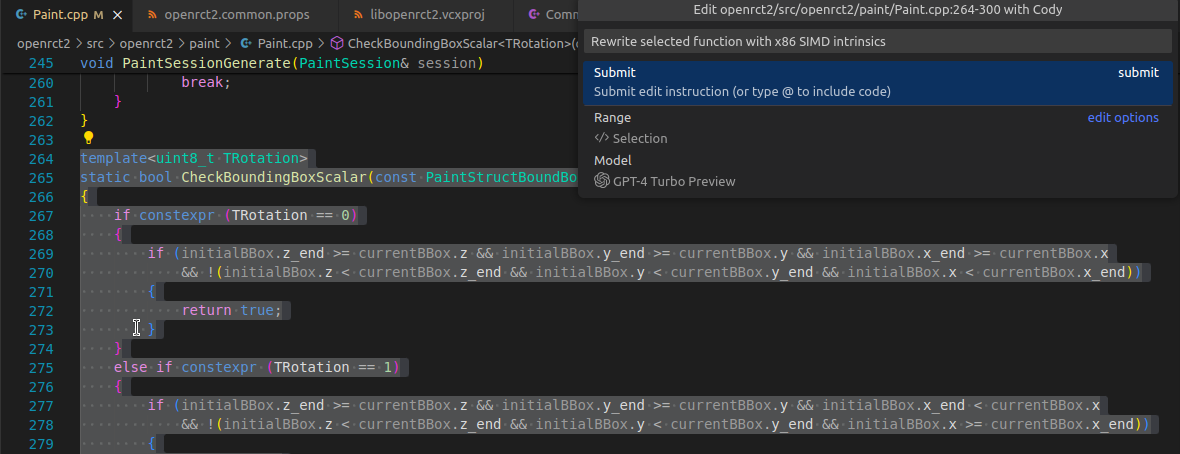
Cody delivers:
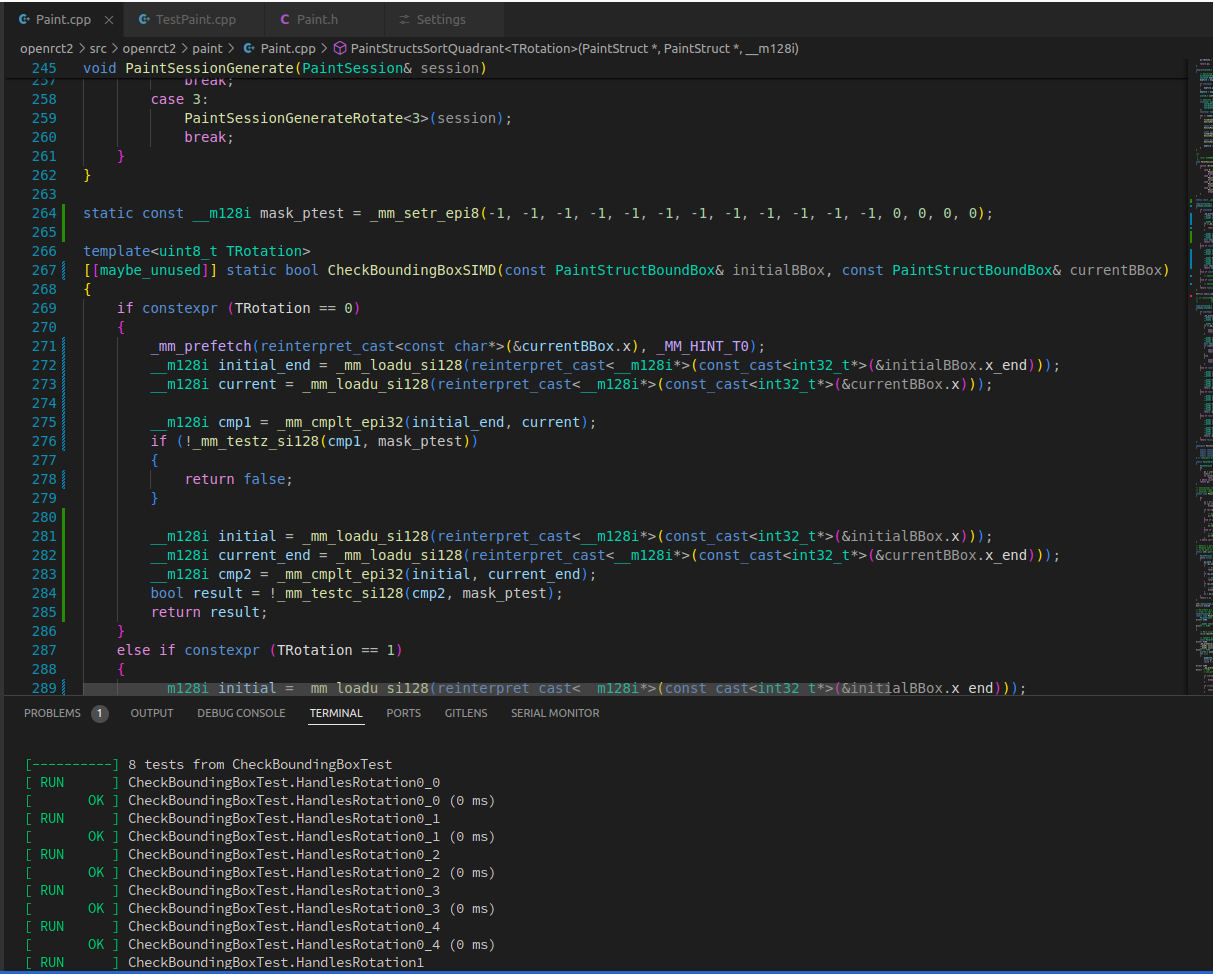
With tests passing, let’s see what kind of performance improvements this delivers:
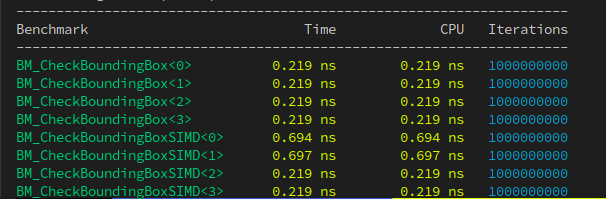
That doesn’t look quite right. 3x slower than original code. Let’s have Cody explain what’s wrong with this approach: Can you explain why the highlighted SIMD code is slower than its scalar equivalent in function CheckBoundingBoxScalar?
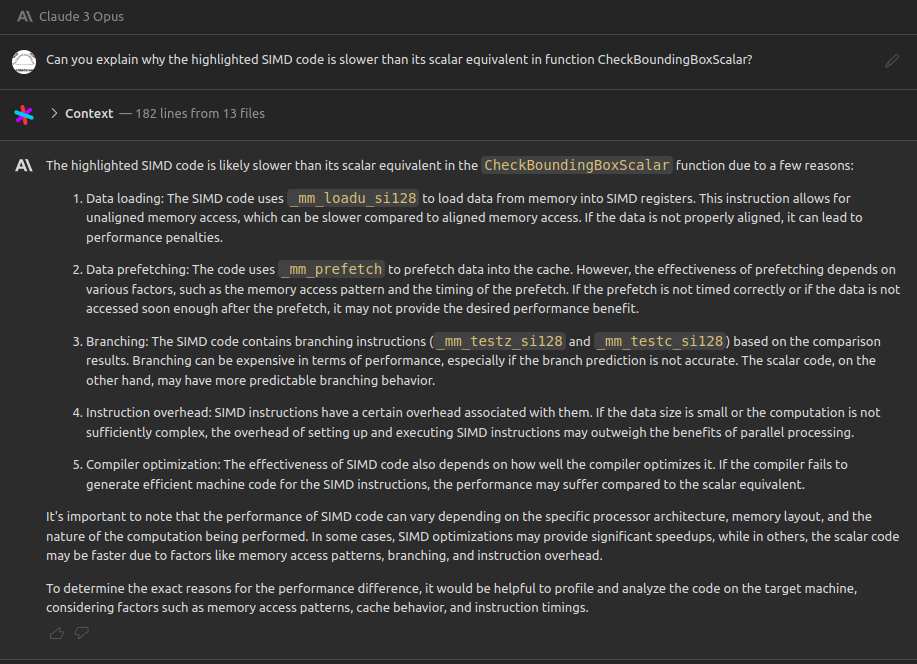
OK, that’s a lot of useful information. It seems the code isn’t bottlenecked on the ALU (arithmetic logic unit), but on memory instead. But then again, Cody mentioned the prefetch effectiveness depends on various factors and I’ve decided to test if moving the prefetch to a place earlier in the paint ordering loop would improve performance.
Using another benchmark implemented earlier and a known performance-sensitive map, the code with no prefetch results are:

And with prefetch implemented:

A ~5% win, for something that initially had been 3x slower! I’m happy with that result. Cody helped me finally find the bottleneck and implement a decent improvement. You can check the merged PR here.
Conclusion
SIMD optimizations can be a powerful tool for improving performance, but it's crucial to understand the underlying bottlenecks and test assumptions thoroughly. With the assistance of AI tools like Cody, developers can streamline the process of writing tests, benchmarks, and optimized code, ultimately leading to better performance gains. Oh, and if you want to download and play OpenRCT2 yourself, check it out at https://openrct2.org/downloads
Cody can help you code faster, improve your productivity, and unlock new knowledge. Give Cody a try today!