The anatomy of an AI coding assistant

Have you ever wondered how an AI coding assistant works?
We’ve been working on our AI coding assistant, Cody, for a while now, and over time we’ve learned that really, context is king.

If you ask ChatGPT a coding question about your particular codebase, it won’t be able to answer it because it doesn’t know anything about your codebase.
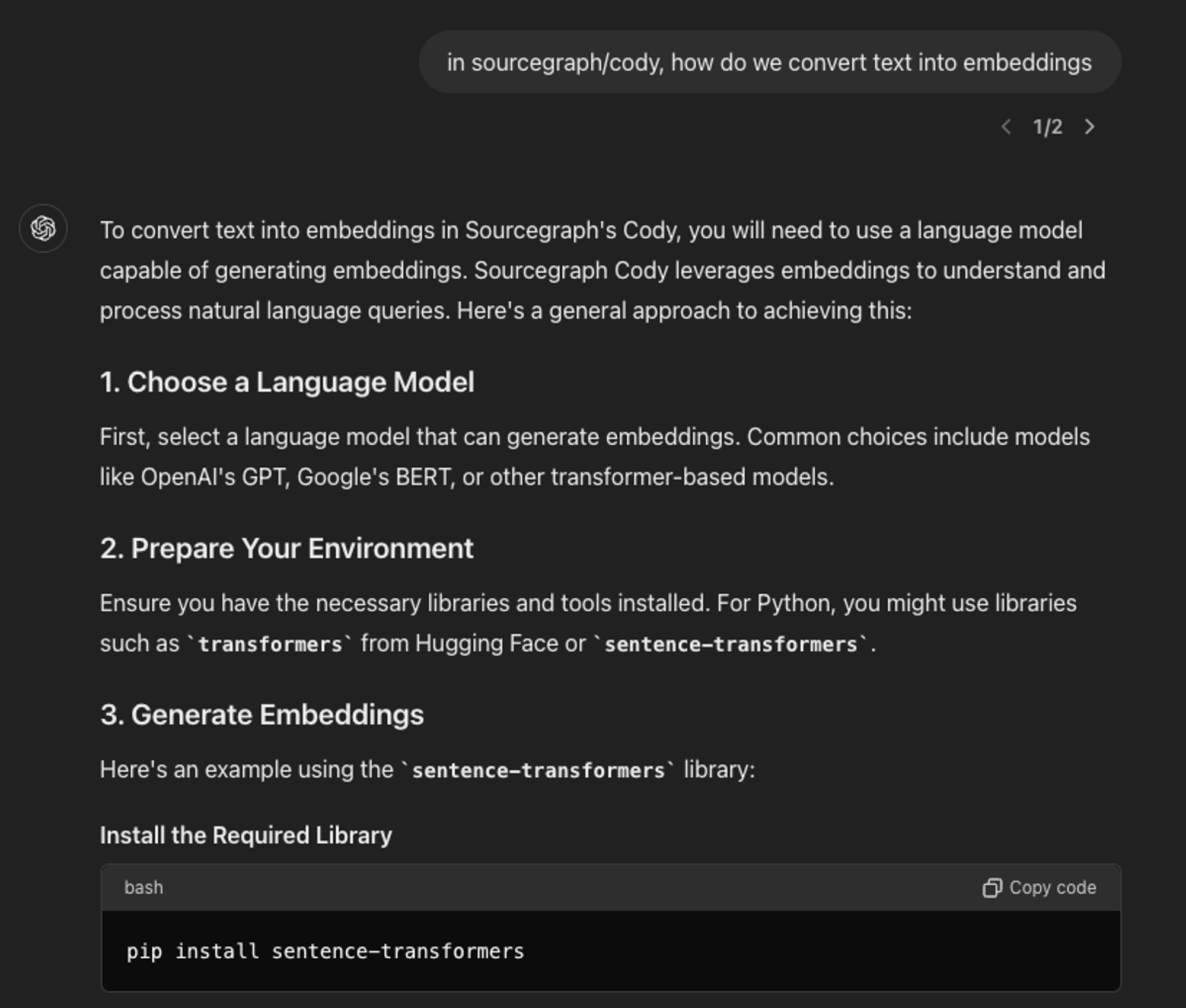
Even if it happens to be open source, the answer you get might be outdated or not accurate enough.
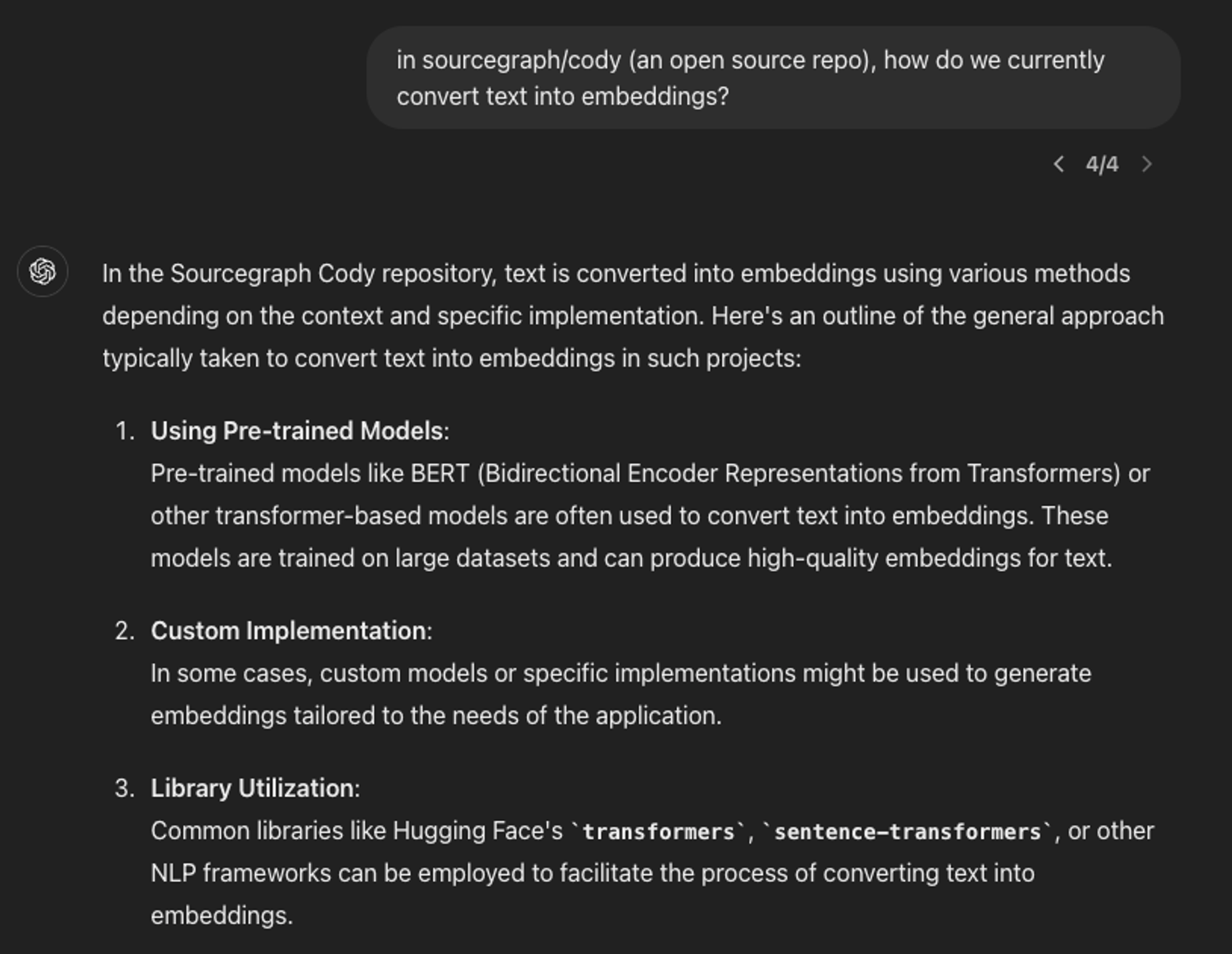
So, by fetching the right parts of your codebase and giving them to your AI coding assistant, the underlying AI model is able to come up with much better answers.
Over the past year or so, we’ve learned a lot about what works for fetching the right context for an AI coding assistant. In this post, I’m going to share some of those learnings and uncover how it works under the hood.
An AI coding assistant - a product of products
The reality is, if you look at a coding assistant like Sourcegraph Cody, it’s not a single product—it’s many products put together. You have autocomplete, which makes suggestions as you code that keep you in flow. Then there’s chat, which allows you to ask questions of and generate code that fits in your codebase. Cody also has a feature that automates quick inline code changes with natural language, and another one that generates unit tests.
Each of these features works very differently from one another. The mental model of the user and the requirements are different for each. For autocomplete, speed is key. You want it to be very fast and accurate enough so that it doesn’t interrupt the programmer’s flow. On the other hand, for chat, accuracy and the quality of the responses may be more important.

When generating tests, there may be additional requirements. For example, if you’re looking at a file and want to add tests to it, you need to quickly detect if a test file for that file already exists. So, when we say “coding assistant,” it might sound simple, but it’s actually a product of products—multiple products put together to create a comprehensive experience.
In this post, we're going to take a look at how context fetching works for each particular feature - chat, autocomplete, generating tests, and editing code.
How context fetching works for chat
Chat allows you to ask questions about your codebase and generate code that's tailored to work within your codebase. For this, we want a few things:
- Conversation history: In a given chat session, we record previous messages as they may contain relevant context for the user's next request.
- Code search: We fetch the most relevant code snippets related to the user's query from the codebase using search, similar to how a human dev might search for these code snippets.
- User control: Users should have the ability to mention specific files and provide those directly to the model with an option to reference external sources like Slack threads or Notion documents to enrich the context further.
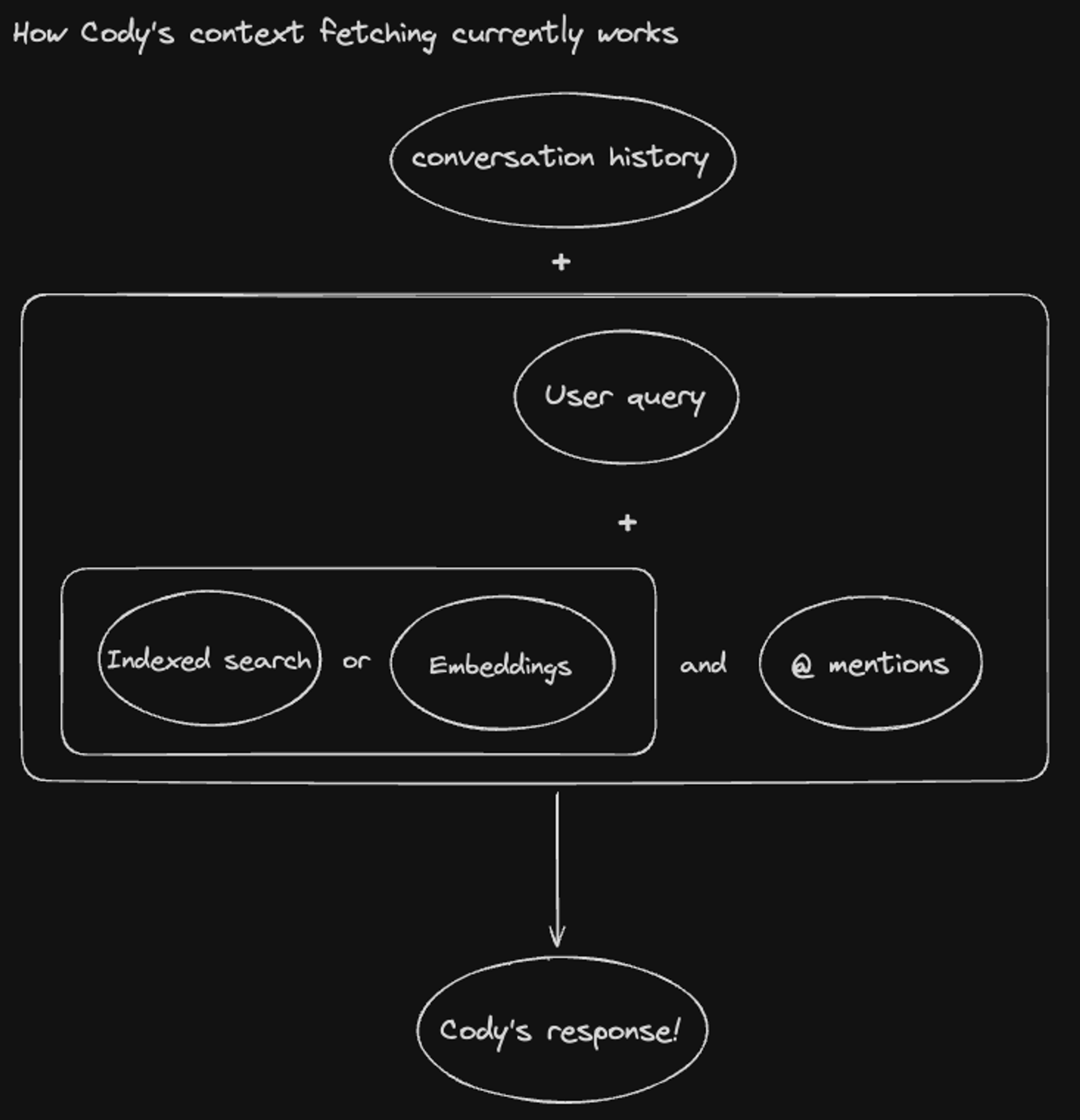
For code search, we use two techniques for surfacing relevant snippets:
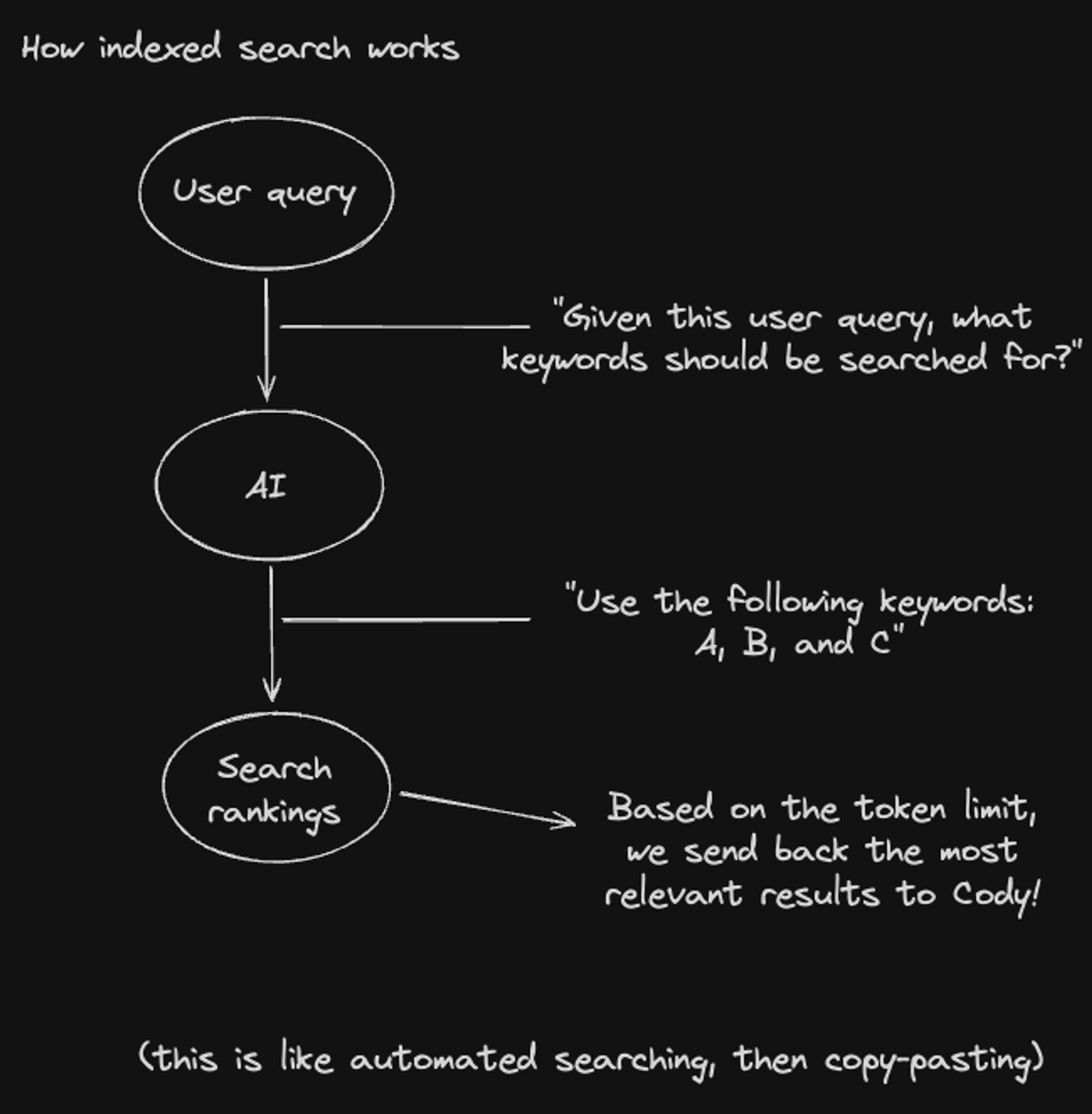
- Keyword search: We first perform a 'query understanding' step, which interprets the user's query and crafts a set of code searches to perform. This step pulls out important entities like file paths and symbols, as well as key terms and their variants. We use both traditional search techniques, and a lightweight LLM to process queries.
In particular, with the June release, we made several improvements: Enterprise context now rewrites queries, enabling us to handle longer and foreign-language questions. We also detect filenames and symbols in queries, addressing a class of "easy-looking" questions users expect us to get right.
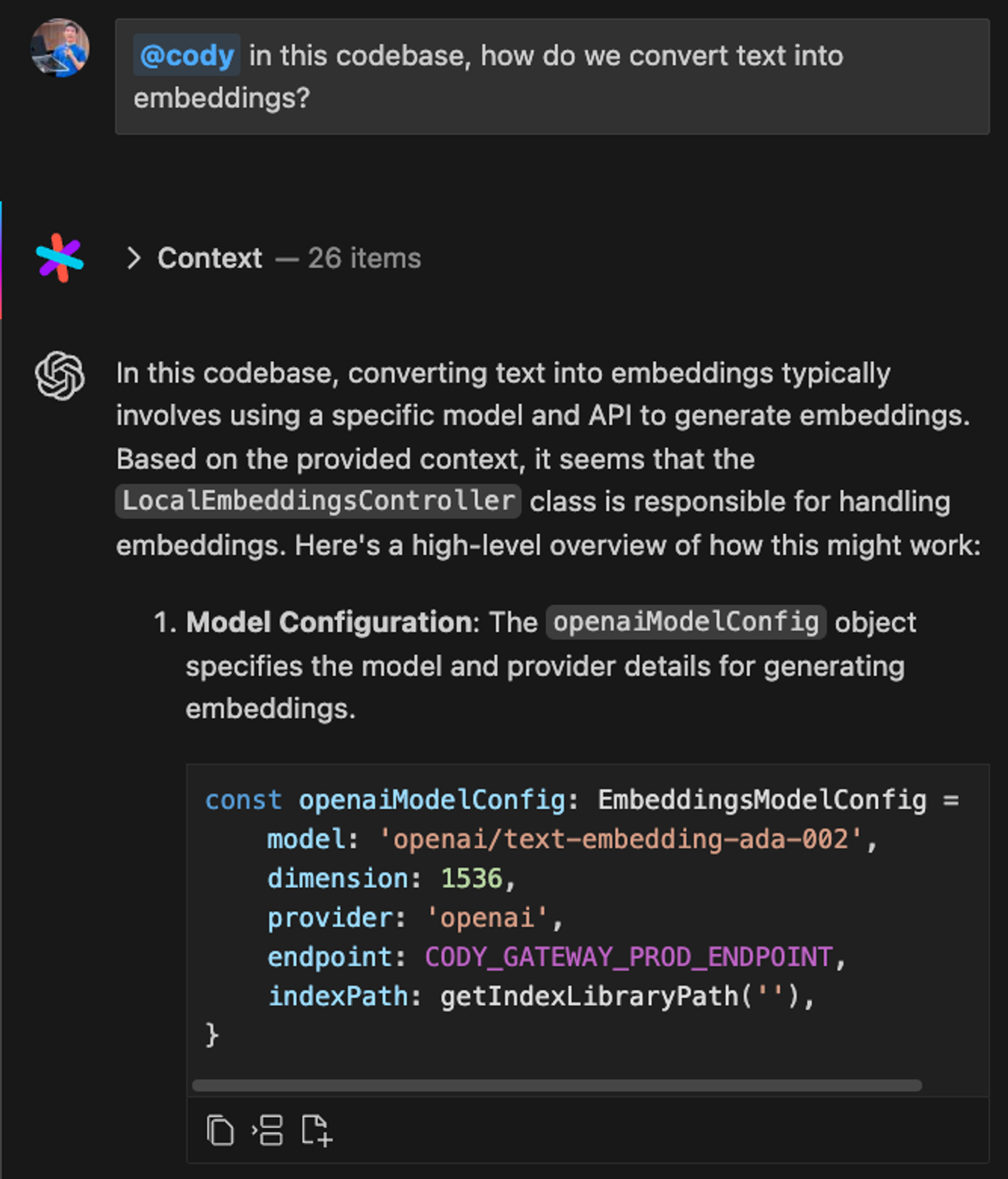
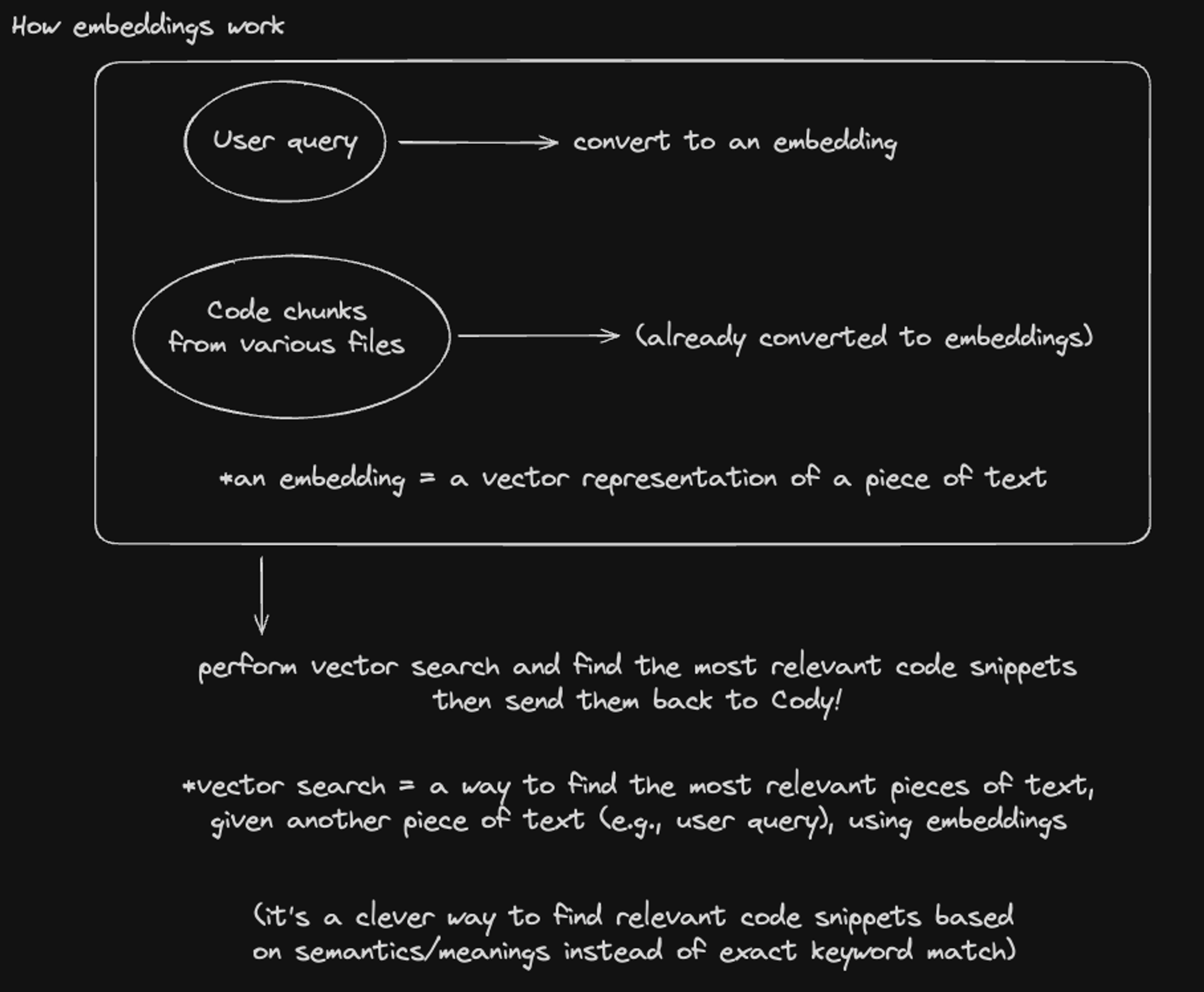
- Embeddings: Embeddings refer to the internal vector of numbers that LLMs use to represent text. When we set up embeddings, we first convert code snippets from various files into embeddings in an indexing step. At query time, we convert the user query to an embedding vector, too. Using these embeddings, we perform vector search to find the most relevant code snippets for the user query.
- To convert code snippets into embeddings, we use either OpenAI’s text-embedding-ada-002 model or Sourcegraph's own model called st-multi-qa-mpnet-base-dot-v1. The choice between these models is determined by a feature flag. The embeddings are stored locally on your machine.
Currently, we default to a mix of both with an option to use one or the other.
Context sources outside of your codebase
In addition to automatic context fetching, we've found that providing a way for the user to manually include context is also helpful. We've done this by letting the user ask questions about specific files by @-mentioning them. More recently, we've realized that there is more context the user sometimes wants to include outside of the codebase, such as documentation, web pages, Slack threads, Linear issues, and Notion documents. We've created an open source protocol called OpenCtx to make it super easy to bring in context from any source.
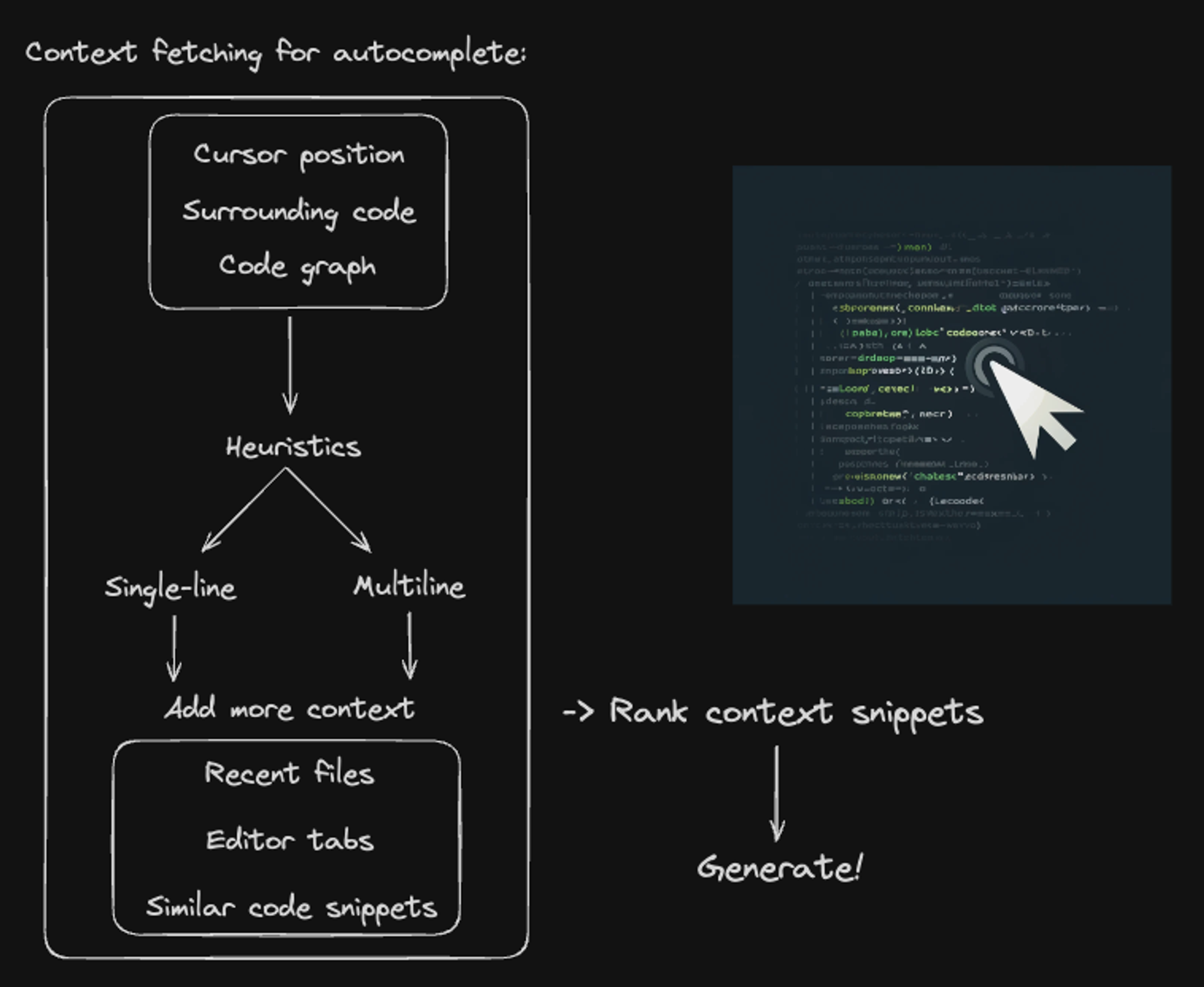
Context fetching for autocomplete
Autocomplete provides code suggestions as you code in your editor. For this feature, we want it to feel as instantaneous as possible because we don’t want to break the flow of the programmer. At the same time, we want to quickly find and identify which code snippets to include as part of the context to provide high-quality suggestions.
For this, we look at a few sources of information: the cursor position, the surrounding code, and the code graph (a code graph is a representation of the relationships and structures within a codebase, mapping entities such as classes and methods to show how they are interconnected). We use the current cursor position within the code graph to determine if the user wants a single-line suggestion or a multi-line suggestion. Once we determine that, we add more context by looking through recent files and open tabs. Within those, we find code snippets related to the code you're currently writing.
For autocomplete, we don't currently use embeddings. Instead, we consider all relevant chunks from the current file, surrounding file, and recently edited files. We compare each of these chunks to the current code being written using something called the Jaccard similarity coefficient. This provides a very fast retrieval mechanism over this set of files, which is crucial for fitting into the latency budget that autocomplete requires. If you’re curious about this, you can check this document for more information about it, and you can even dig into the source code because much of Cody is open source.

Once we create rankings of different code snippets from various sources this way, we combine them using what’s called Reciprocal Rank Fusion. For more details on this, you can read this document.
Context fetching for autocomplete relies mostly on fast classical and compiler-based techniques, rather than LLMs, because we need something that performs very quickly and can be invoked at high volume. As long as the quality of the selected snippets is good enough, the LLM model can use that information to produce high-quality suggestions.
Context fetching for test generation
This feature allows you to select a file and automatically generate tests for it. The requirements for this feature are vastly different from those for chat or autocomplete. For this, we want to be able to detect if there is already a test file for the chosen file. If it doesn’t exist, we want to generate that automatically. Whether you end up generating a new file or finding an existing test file for the chosen file, we want to be able to add relevant files for context.
To achieve this, after creating or finding the test file, we find other test files to understand how tests are written in the given project. This significantly reduces AI hallucinations and ensures we use the appropriate methods and conventions. Without this context, test generation wouldn’t work as well because it might use outdated methods or methods not used in the given project.

Context fetching for editing code
This is a feature that lets you select a block of code and edit it using natural language instructions.
 For this, we automatically retrieve:
For this, we automatically retrieve:
- Surrounding code, both before and after the cursor
- Diagnostic information like warnings and errors
- User-specified context from @-mentions
By including diagnostic information, we're able to provide more appropriate code edits to the selected range of code. With the code editing feature, we currently put greater emphasis on the users prompt and rely on the above context sources to generate high quality code output. In the future, we plan to incorporate code graph context here as well.
A note on evals
Over time, we've developed many ways to evaluate different context-fetching methods as well as the underlying LLM models.
For example, we have:
- a set of ~90 queries we run against open source repos to test the efficiacy of our chat system
- an internal leaderboard that automatically evaluates large language models' effectiveness at the features I mentioned above
- lots and lots of tests that hit our default models and assert various things like non-hallucination, LLMs staying in character, etc.
We've found that developing these testing frameworks is a crucial part of making sure we can keep making progress in our product quality.
Further room for improvement
Even though creating and polishing a context fetching mechanism for each of these features has taken a lot of work, we must admit that there’s still a lot of room for improvement.
Some of the areas we’re still actively working are:
- Underlying LLM models, comparing different models and fine-tuning some of them
- A query rewriting strategy where we have AI rewrite user queries to fit our context-fetching system better
- A smarter way to determine what types of context need to be fetched for each query
Our long-term goal is to create an AI coding assistant that finds the right context for you in a smart way, not just from your codebase, but from any tool or reference source that a human software engineer would use in order to get the job done.
Try Cody
Enjoyed learning about how Cody works? Give it a try and let us know what you think!